

TSB customers face major issues after an IT crisis even 5 weeks after the initial break-down. The setback occurred as the bank was migrating from its legacy systems and the process demanded to transfer a data of over 5 million users to new technology. Although the bank pre-informed the users that online banking will be closed over the weekend, the customers got frustrated when the glitches continue to show up long after the mentioned time period.
Online banking being a vital part of daily lives soon hit the users as they were unable to access the accounts, pay bills or shop online and started a social media uproar. Some wanted to takeout their money immediately and others filed multiple complaints to support which they said were poorly handled. The problem with TSB online login caused major distress among the public. 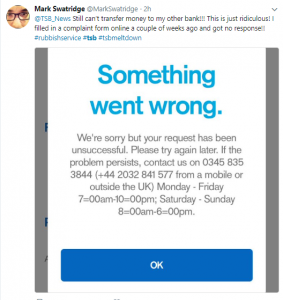
The bank is now facing huge customer loss and fines from financial authorities. The higher authorities say they are fixing the system but the reputation losses due to major TSB online banking failures are irreversible.
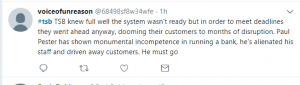
IT failures are likely to happen when dealing with such huge data bases, however, these unfortunate situations can be avoided through proper project planning and test-runs. Here are some lessons we can learn from the incident:
Risks of Running Legacy Systems
Most of the financial institutions are still running on legacy software while the technology used to build them has long been dead. Regular migrations and updates should be a vital part of the IT strategy of enterprises to avoid major failures. Not shifting systems timely can lead to shortage of skills which consequently leads to major failures like these.
Migration concerns
When it comes to migrating legacy systems to newer technologies, its always a risky job. Looking into the costs and risks of replacing the core makes many organisations back-off and delay until change is inevitable. If systems are timely migrated many such failures can be avoided. Furthermore, if the shifts have to take place, there is a need of proper strategy planning and a detailed risk assessment procedure.
As much as choosing a suitable migration method is important, it is very vital to calculate the down time and a steady plan to roll back if things start leading to a break-down.
Strong IT Architecture
As data starts pilling up in the system, there is an increasing security concern and a need to have a secure backup maintained in case of any IT break-down. Building up a powerful IT architecture is the only way to handle the huge databases and reduce risks. The processes going on in a system must be properly documented and run through teams rather then patching up glitches by any means possible.
Rigorous testing
Testing complex systems is not an easy job. It is suggested that even detailed testing can only fix up to 85% of bugs. Each and every aspect has to be considered in detail and reviews must be taken from all the concerning departments. The risk chances are likely higher in huge data-bases which demands them to be given a good time without rushing to deployment.
No to stubborn deadlines
It is without the doubt that the hassle caused by the TSB breakdown has much to do with the tough timetables. Inflexible deadlines can be a major cause of failure as sometimes the estimated delivery time comes has less room for testing procedures which forces the team to deploy even with doubts. Large-scale institutions must always keep enough room for detailed reviews to avoid unfavorable circumstances.
Risk Analyses
Companies must always keep all the situations in mind before going live. A proper risk management strategy is the core of any development project and the lack of one can lead to disasters. The risks of things going wrong have to be considered the most when dealing with public and massive users. The public dependency on TSB for daily transaction led to a much bigger panic which, worse, was poorly addressed.
Lessons to learn
TSB business banking is huge and taking risks with such large clientele is never a good option. When carrying out huge migrations, hassle is not the answer. Testing must be given the due time and deadlines must be extended when a chance of failure is lurking over. Moreover, IT departments can’t alone handle disasters like these and the role of higher management and an active customer support is equally important in disaster situations.